

DynamoDB provides an incredible set of no-frills features for building apps and services. It has consistent performance at any scale. Very low operational pain. Simple cost model. Missing from that list? Optimizing an application to use DynamoDB correctly can be a ton of work, especially if you haven’t done it before. And even if you have, it kind of sucks.
At Stately we’re building a new type of cloud-native database that optimizes for change. StatelyDB uses Elastic Schema to make it easy and safe to model your data and make changes to that data model, with built-in optimization for how your data is stored. We’re also big fans of DynamoDB, which is why we chose it as our first storage engine. We think if you like the benefits of DynamoDB then you’re going to love StatelyDB because it gives you the best of what DynamoDB has to offer but turbo-charged with a real schema. As we’ll explore in this article, you’re going to want to be able to iterate on your data model without having to sacrifice the optimizations that squeeze the best out of DynamoDB.
Let’s walk through an example of using StatelyDB using a DynamoDB data modeling example from the DynamoDB documentation which describes an application for tracking bookmarks.
We start with a really simple data model that defines Customers and Bookmarks. A Customer has zero or more Bookmarks, with a Bookmark containing a foreign key field named customerId. Here’s a diagram of the data model:

One of the best practices for using DynamoDB effectively is to think about the access patterns for your data up front. This is a departure from the way you would use a relational database where the data model is defined for efficient storage and then later accessed ad-hoc using SQL and a mess of indexes. In the case of our example, the DynamoDB article recommends following a “single-table” design that is optimized around efficient reads:
In my case, I know that most of the times the application is showing, for a specific customer, a summary of the customer information, and the list of customer bookmarks.
Wouldn’t it be great if I could retrieve all this information with a single query?
Well, sure, that sounds great. In other words, we want to be able to retrieve everything about a customer and their bookmarks in a single query by Customer ID (eg: 123). The way this is accomplished in DynamoDB is to use a single table that can store different types of Items (i.e. “rows”) representing either a Customer or a Bookmark. Each Item in the table shares a common Partition Key, which means each lookup can be performed in constant time. After retrieving the Items it is up to the developer to inspect the Sort Key to determine what the Item represents. AWS refers to this method of storing different kinds of data in the same table as “overloading”.
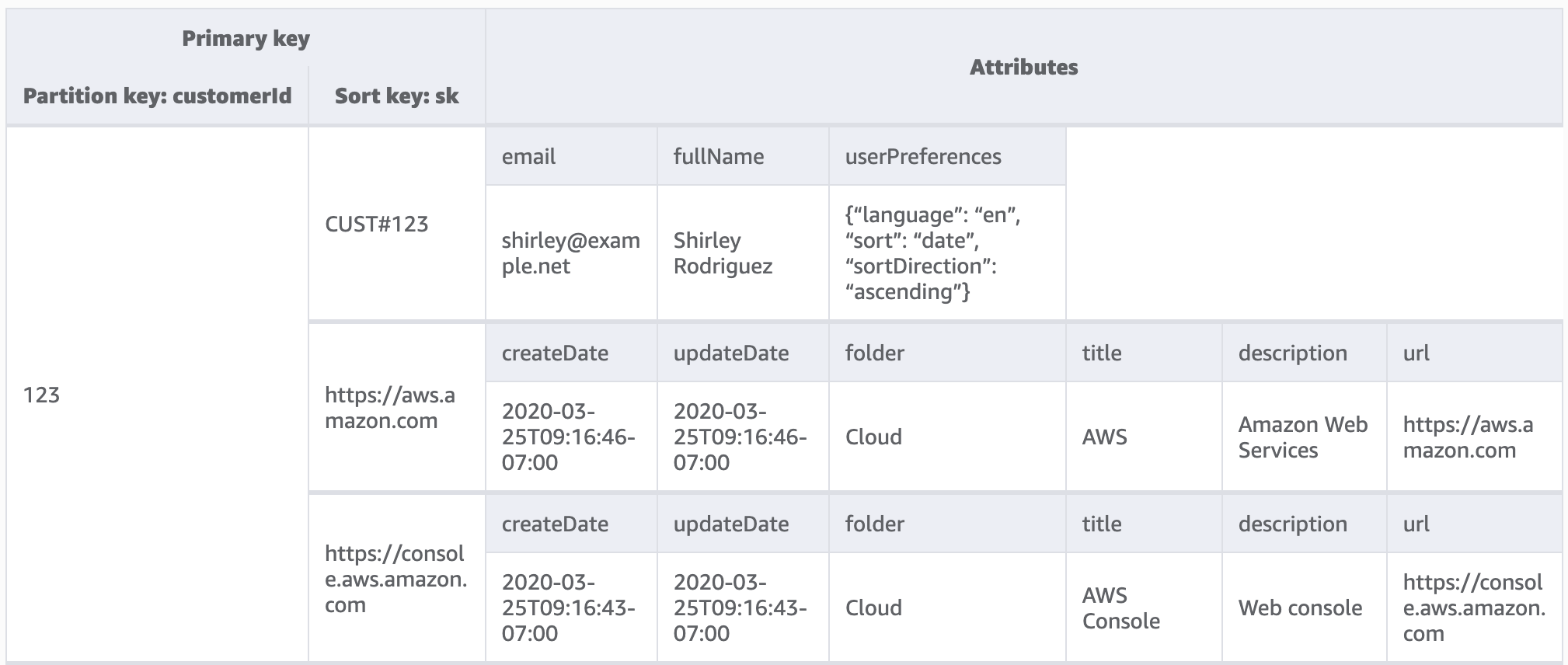
The table design above is indeed optimized for our retrieval use case, but you would be hard pressed to describe it as intuitive. It makes more sense if you step back and think about the underlying architecture of DynamoDB, which is a system that makes use of Partition Keys to resolve which storage node a particular Item lives at and then a Sort Key to search a B-Tree for the Item.
Designing an application on top of DynamoDB is a lot like an interview question where you’re asked to solve a puzzle but you can only use a hashmap as your data structure. Sure, there’s going to be a “correct” way to solve that puzzle but you’d likely never have gotten there without being given that constraint.
Aside from the awkward ergonomics of interacting with this table there are a few hidden landmines that aren’t obvious from the article:
456 attempts to create a Bookmark with a url of “CUST#123”?The author of the article includes a warning that is easy to overlook:
When using a NoSQL database, you should design your data model to optimize for the application’s access patterns. You should ask yourself:
You shouldn’t start the design of the data model if those questions are not clear, otherwise you risk to update it too often, slowing down development.
Uh oh. What if I want to be able to change my mind in the future? What if I don’t know all my access patterns yet? Do I have to design it all ahead of time and pay for patterns I’m not going to use right away?
In contrast, let’s look at what this application would look like using Elastic Schema in StatelyDB.
import { itemType, uuid, string } from "@stately-cloud/schema";
itemType("Customer", {
keyPath: [
"/c-:customer_id",
"/e-:email"
],
fields: {
customer_id: { type: uuid, initialValue: "uuid" },
email: { type: string },
full_name: { type: string },
user_preferences: { type: string }
}
});
itemType("Bookmark", {
keyPath: [
"/c-:customer_id/f-:folder/b-:bookmark_id",
"/u-:url_hash"
],
fields: {
bookmark_id: { type: uuid, initialValue: "uuid" },
customer_id: { type: uuid },
folder: { type: string },
title: { type: string },
description: { type: string },
url: { type: string },
url_hash: { type: bytes },
}
});We start by defining Customer and Bookmark Item types, with the same set of fields and types from the article. StatelyDB handles generating the UUIDs for our Customer Items automatically, which is already a nice convenience compared to doing it ourselves in the application if we were using DynamoDB. And, since StatelyDB generates real typed objects for us in our favorite languages, we can ensure that every Item we write is going to be valid and conform to this schema, without having to write any manual validation or type-mapping code.
So what about access patterns? In addition to the teaching use case of being able to retrieve all data for a Customer by their ID, the article describes retrieving Customer Items by email address and retrieving a Bookmark by URL. We accomplish all three in StatelyDB using Key Paths.
StatelyDB supports listing Items by Key Path prefix, which means we can easily query across different Item types by following a certain naming convention. This is similar in spirit to what can be accomplished in DynamoDB with overloading, but we think it’s a heck of a lot easier to reason about. In our Elastic Schema definition we created a primary Key Path for each Customer of /c-:customer_id. Then when we modeled a Bookmark we created a primary Key Path that followed a naming convention where the Bookmark is nested under the /c-:customer_id path, which gives us a Key Path of /c-:customer_id/f-:folder/b-:bookmark_id. What this means is that we can use StatelyDB’s List commands to ask for Bookmark Items easily by Customer ID or folder.
Here’s what it would look like to query for both Customer and Bookmark Items in a single List operation:
const prefix = keyPath`/c-${customerId}`;
let iter = client.beginList(prefix, {
limit: 10,
});
let customerInfo;
let bookmarks = [];
for await (const item of iter) {
if (client.isType(item, "Customer")) {
customerInfo = item;
} else if (client.isType(item, "Bookmark")) {
bookmarks.push(item);
}
}By contrast, here’s the DynamoDB example:
const data = await docClient
.query({
TableName: "CustomerBookmark",
KeyConditionExpression: "customerId = :customerId",
ExpressionAttributeValues: {
":customerId": customerId,
},
Limit: 10
})
.promise();
const customerInfo = data.Items.find((item) => item.sk.startsWith("CUST#"));
const bookmarks = data.Items.filter((item) => !item.sk.startsWith("CUST#"));Note that in the StatelyDB version we’re getting back real Customer and Bookmark types, whereas the DynamoDB version is autoconverted untyped JSON objects.
We defined a Key Path alias for our Customer Item in the format of /e-:email which lets us perform a simple Get request. When using StatelyDB we can just grab the Customer Item in one line, with the result being an object of type Customer:
const item = await client.get("Customer", keyPath`/e-${email}`);By comparison, the following snippet is what an equivalent request would look like fetching from DynamoDB. However in this case it’s up to you to figure out what you got back. Note that this call requires setting up a global secondary index named ByEmail ahead of time, as explained in the article.
const data = await docClient.query({
TableName: 'CustomerBookmark',
IndexName: 'ByEmail',
KeyConditionExpression: 'email = :email',
ExpressionAttributeValues: {
':email': email
}
}).promise();
We again use a Key Path alias, this time for a Bookmark Item, in the format of /u-:url_hash. Our Key Path alias uses a hash of the URL to keep our aliases tidy (eg: /u-5ec0d09f335cf82cdaf13dbf1d543f97 instead of /u-http://www.cnn.com/).
const item = await client.get("Bookmark", keyPath`/e-${md5(url)}`);The DynamoDB sample again uses a secondary index, but is otherwise unsurprising:
const data = await docClient.query({
TableName: 'CustomerBookmark',
IndexName: 'ByUrl',
KeyConditionExpression: 'url = :url',
ExpressionAttributeValues: {
':url': url
}
}).promise();
Engineering your code to run on DynamoDB isn’t rocket science, but it does take work. After walking through these examples it’s clear that while DynamoDB offers powerful capabilities, it often requires complex workarounds and careful planning to handle evolving data needs. StatelyDB, with its Elastic Schema, aims to provide a more flexible and developer-friendly approach.
Let’s recap the key advantages we’ve seen:
These benefits add up to a significant improvement in developer experience and productivity. But don’t just take our word for it - we invite you to experience the difference yourself.
Release notes, roadmap, security updates.
