

Porting a popular web app from Postgres to StatelyDB.
Destiny Item Manager (DIM) is an open-source, community developed companion app for Bungie’s Destiny and Destiny 2 video games. DIM is extremely popular among Destiny players, with over 500,000 monthly active users and a total user base of over 2.5 million users. While it largely operates as a browser-based progressive web app that talks directly to the game’s APIs, DIM also has its own cloud service that it uses to store and sync extra user data across different instances of the app. For example, you can create a loadout (a collection of weapons and armor to use in the game) on your laptop and then tweak it or apply it from your phone.
I just happen to have been DIM’s primary developer (but far from its only contributor) for almost the last decade, and the sole developer of DIM’s API service. When we started StatelyDB, I knew DIM could be a great test bed for migrating a real, medium-sized workload and seeing how it went.
I didn’t want to migrate just because it’s a great opportunity for a demo. DIM’s API is implemented as a NodeJS service talking to a hosted Postgres database, and while that has worked OK, there’s a number of things that aren’t ideal about it:
Given all that, I’d been kind of stalled on adding new features to the API, knowing that the effort required was higher than the effort to work on other things in my scant free time. Switching to StatelyDB would let me get back to adding those new features.
My plan for moving over to StatelyDB required a few different steps:
DIM has a handful of different types of data that it stores on behalf of users. Crucially, each user has their own private set of data (their profile). There’s no data shared between users. However, each user has several different types of data in their profile, and the app fetches all of it in a single request every 10 minutes. This is a great fit for a non-relational, partitioned document database like StatelyDB, especially since StatelyDB makes it easy to have different types of data all grouped together under a single user.
The main types of data DIM needs to model are:
itemType('Loadout', {
keyPath: '/p-:profileId/d-:destinyVersion/loadout-:id',
fields: {
id: { type: uuid },
name: { type: string },
notes: { type: string, required: false },
classType: { type: DestinyClass, required: false },
/** List of equipped items in the loadout */
equipped: { type: arrayOf(LoadoutItem), required: false },
/** List of unequipped items in the loadout */
unequipped: { type: arrayOf(LoadoutItem), required: false },
/**
* Information about the desired properties of this loadout -
* used to drive the Loadout Optimizer or apply Mod Loadouts
*/
parameters: { type: LoadoutParameters, required: false },
/**
* When was this Loadout initially created? Tracked automatically
* by the API - when saving a loadout this field is ignored.
*/
createdAt: {
type: timestampMilliseconds, fromMetadata: 'createdAtTime',
},
/**
* When was this Loadout last changed? Tracked automatically
* by the API - when saving a loadout this field is ignored.
*/
lastUpdatedAt: {
type: timestampMilliseconds, fromMetadata: 'lastModifiedAtTime',
},
destinyVersion: { type: DestinyVersion },
profileId: { type: ProfileID },
},
});
// Definitions for LoadoutParameters, LoadoutItems, etc.For each type of data, I went through and started from my existing TypeScript definitions for the types returned by the API, and translated those into StatelyDB’s Elastic Schema. After I’d done one or two by hand, I actually just asked GitHub CoPilot to do the rest, and it got me most of the way—I only needed to tweak some data types and add some validation that was implicit in the SQL version.
After the schema was designed and committed to StatelyDB, I generated TypeScript code with the Stately CLI to access all of my new data types, and then I set to work on the operations that update and query the data. I started by wholesale copy/pasting the Postgres access layer code into a new folder, and then went through each helper and translated it to the StatelyDB APIs. In general, the StatelyDB code was more straightforward and easier to understand than the SQL code, but there were a few things I needed to be careful about:
1. I needed to write translation functions to convert between StatelyDB’s generated items and the structures I accept and return from the API. They’re very close, but not exactly the same - for example in the StatelyDB version a number might be represented as a BigInt, whereas in my JSON API they were represented as a string. In more than a few places I had to add code to handle invalid data that had been saved into the Postgres database that StatelyDB would not accept, since the StatelyDB schema is much more precise.
export function convertLoadoutFromStately(item: StatelyLoadout): Loadout {
return {
id: stringifyUUID(item.id),
name: item.name,
classType: item.classType as number as DestinyClass,
equipped: (item.equipped || []).map(convertLoadoutItemFromStately),
unequipped: (item.unequipped || []).map(convertLoadoutItemFromStately),
createdAt: Number(item.createdAt),
lastUpdatedAt: Number(item.lastUpdatedAt),
notes: item.notes,
parameters: convertLoadoutParametersFromStately(item.parameters)
};
}
export function convertLoadoutToStately(
loadout: Loadout,
platformMembershipId: string,
destinyVersion: DestinyVersion,
): StatelyLoadout {
return client.create('Loadout', {
id: parseUUID(loadout.id),
destinyVersion,
profileId: BigInt(platformMembershipId),
name: loadout.name || 'Unnamed',
classType: loadout.classType as number,
equipped: (loadout.equipped || []).map(convertLoadoutItemToStately),
unequipped: (loadout.unequipped || []).map(convertLoadoutItemToStately),
notes: loadout.notes,
parameters: convertLoadoutParametersToStately(loadout.parameters),
createdAt: BigInt(loadout.createdAt ? new Date(loadout.createdAt).getTime() : 0n),
lastUpdatedAt: BigInt(loadout.lastUpdatedAt ? new Date(loadout.lastUpdatedAt).getTime() : 0n),
};
}2. A few operations relied on complicated SQL upsert statements to either insert new data or update existing data, or to merge existing data with incoming data. I replaced these with more straightforward read-modify-write transactions that load the existing item, mutate it, and save it back. It’s more code, but it’s really clear what’s going on vs. the SQL statements:
export async function updateItemAnnotation(
platformMembershipId: string,
destinyVersion: DestinyVersion,
itemAnnotation: ItemAnnotation,
): Promise<void> {
const tagValue = clearValue(itemAnnotation.tag);
const notesValue = clearValue(itemAnnotation.notes);
if (tagValue === 'clear' && notesValue === 'clear') {
// Delete the annotation entirely
return deleteItemAnnotation(platformMembershipId, destinyVersion, itemAnnotation.id);
}
await client.transaction(async (txn) => {
let existing = await txn.get(
'ItemAnnotation',
keyFor(platformMembershipId, destinyVersion, itemAnnotation.id),
);
if (!existing) {
existing = client.create('ItemAnnotation', {
id: BigInt(itemAnnotation.id),
profileId: BigInt(platformMembershipId),
destinyVersion,
});
}
if (tagValue === 'clear') {
existing.tag = StatelyTagValue.TagValue_UNSPECIFIED;
} else if (tagValue !== null) {
existing.tag = StatelyTagValue[`TagValue_${tagValue}`];
}
if (notesValue === 'clear') {
existing.notes = '';
} else if (notesValue !== null) {
existing.notes = notesValue;
}
if (itemAnnotation.craftedDate) {
existing.craftedDate = BigInt(itemAnnotation.craftedDate * 1000);
}
await txn.put(existing);
});
}3. I took a lot of care in designing the key paths for my new items. As we’ll explore later in this article, by choosing key paths with the same prefix, I set myself up to be able to query all of a user’s data in one List operation. You can read more about how the key paths are designed in the README for DIM’s schema. For example, this tree of paths means that I can get all of the data for a given profile ID and destiny version at once:
/ia-:id: ItemAnnotation/loadout-:id: Loadout/search-:qhash: SearchIn this phase I concentrated on replicating my old database access layer exactly, even though I knew I could choose some more efficient patterns in StatelyDB. The reason for this is that I also copy/pasted my entire test suite, so I could run the same tests against a new data layer implementation. This gave me a bunch of confidence that I could easily swap in the StatelyDB code without having to rewrite everything else in my service. Optimizing access patterns could be done later.
Before I got to migrating all the user data, I wanted to try out StatelyDB on some simpler use cases. These were the first I migrated over because they were comparatively small amounts of data or traffic:
I wanted to be able to migrate users one at a time. This fit perfectly with the fact that each user’s info is independent from every other user’s, so I could move all of one user’s info into StatelyDB while leaving other users in Postgres. To keep tabs on all this, I made a new Postgres table called migration_state that tracked the state of each account. I could have stored this data in StatelyDB instead of Postgres—I only chose Postgres because it was the starting-point system.
For each user account I kept track of the following data:

The default for this table, if there isn’t a row, is to be in the “Postgres” migration state. Whenever the server goes to read or write data for a user, it first loads the migration state. Reads get dispatched to Postgres or StatelyDB depending on where the data lives. The “Migrating” state is a bit trickier. I chose to block writes while migrating because my goal was to do something simple and relatively quickly. In more high-stakes migration scenarios I would have added more states for dual-write or shadow-write modes, where reads and writes go to both Postgres and StatelyDB in parallel, and it publishes metrics if they are different. That’s what we did when we migrated billions of conversations for Snapchat, but I chose a less careful route for my hobby project.
The migration itself was set up to happen on demand. Whenever the user updated their profile, the server would check to see if the user should be migrated. Initially only a few hand-picked accounts were set to migrate, but eventually I used a hash of the user ID to implement a percentage rollout. If the account should be migrated (and it hadn’t already failed too many times), the server would perform a full migration before accepting the write. This meant reading all the user’s profile data into memory from Postgres, and then bulk-inserting it all into StatelyDB. If that was successful, we’d update the migration state for the account to “Stately”, and they’d use StatelyDB from then on.
I spent a few weeks dialing up the percentage of users who would get migrated on demand. Every time I increased the dial, there would be a flurry of on-demand migrations, which would slowly die out as the regular users got migrated. I was cautious here mostly to protect the Postgres database, as the DynamoDB table backing my StatelyDB store was auto-scaling like a champ.
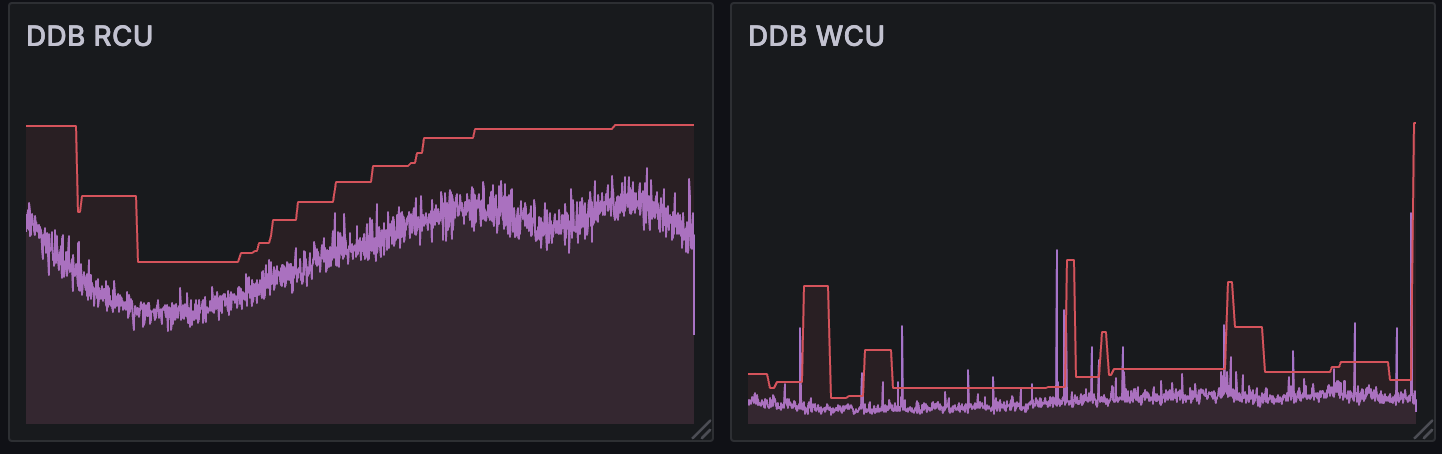
Eventually the dial reached 100%, meaning any new or returning user would be automatically migrated whenever they used the app. This accounted for quite a lot of users, but there was still a long tail of inactive users, whether they no longer used DIM or only play Destiny occasionally. To migrate them, I write a script that I ran on my laptop that performed the exact same migration operation the server would do on demand, but driven off of a query that returned un-migrated accounts. There were only a couple million users to migrate this way, so it was easy enough to leave it running on my laptop for a few days slowly migrating data.
Once all the users were migrated, I updated the code to no longer consult the migration state table, and disconnected it from Postgres entirely. I also went through and updated a lot of my access patterns now that I didn’t need to support two different databases. There were two major changes there:
I’m especially excited to have things migrated over to StatelyDB because I’m now free to implement a lot of the new data types that I’ve had on my mind. Adding new data types to my schema is super simple, and it’s way easier to describe my data model since the schema lets me declare real data types and validations right in-line. This is just the beginning of DIM’s new life on StatelyDB: I’ll have more posts in the future explaining what I’m able to build from here.

